At the end of Chapter 10, we had built a masterpiece. Using a Finite Field Kasteleyn engine, the Chinese Remainder Theorem, and OpenMP, we solved a massive $4096 \times 4096$ domino grid in 6 minutes.
I thought the journey was over. I started writing the drafts for this very blog series.
But then I shared a draft with my friend Anton. He read through the math, paused, and mentioned that he had seen a 1D version of Kasteleyn’s formula. A few minutes later, he sent me a screenshot of an excerpt from a Russian combinatorics textbook.
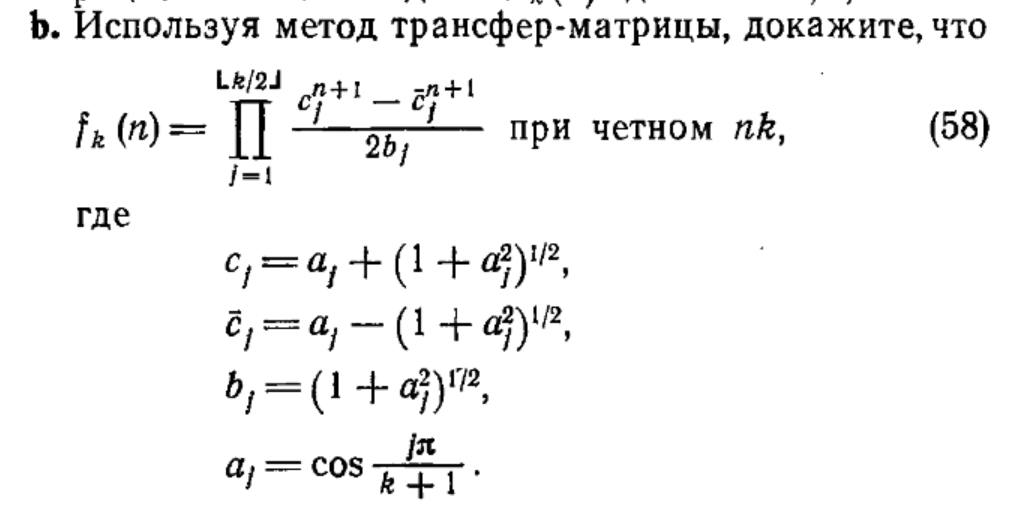
It was a formula derived using the transfer-matrix method, and looking at it fundamentally changed everything I thought I knew about this problem.
The 1D Formula
The formula in the textbook evaluates an $n \times k$ grid using a single product loop instead of a double product loop:
$$f_k(n) = \prod_{j=1}^{\lfloor k/2 \rfloor} \frac{c_j^{n+1} - \bar{c}_j^{n+1}}{2b_j}$$Where the internal variables are defined as:
- $a_j = \cos \frac{j\pi}{k+1}$
- $c_j = a_j + \sqrt{1 + a_j^2}$
- $\bar{c}_j = a_j - \sqrt{1 + a_j^2}$
- $b_j = \sqrt{1 + a_j^2}$
At first glance, this looks like a nightmare for our C++ engine. Our engine relies on Finite Fields ($\mathbb{F}_p$) to keep everything as perfectly exact, native 64-bit integers. If we try to evaluate this textbook formula modulo a prime $p$, we run straight into a brick wall: the square root.
Finding the modular square root of $(1 + a_j^2)$ requires complex algorithms like Tonelli-Shanks, and if $(1+a_j^2)$ isn’t a quadratic residue modulo our prime, the math completely breaks down.
But if you look closely at the structure of that fraction, there is a legendary mathematical cheat code hiding in plain sight.
The Lucas Sequence Bypass
Look at the main fraction:
$$\frac{c_j^{n+1} - \bar{c}_j^{n+1}}{2b_j}$$Notice that $c_j - \bar{c}_j$ is exactly equal to $2\sqrt{1+a_j^2}$, which is exactly $2b_j$. So the fraction is really:
$$\frac{c_j^{n+1} - \bar{c}_j^{n+1}}{c_j - \bar{c}_j}$$Does that structure look familiar? It is exactly Binet’s formula! But it’s not the Binet formula for the standard Fibonacci sequence. It is the formula for a generalized sequence created by the roots of a quadratic equation.
Let’s look at the textbook’s definitions of $c_j$ and $\bar{c}_j$. In algebra, $A + \sqrt{B}$ and $A - \sqrt{B}$ are the roots of a quadratic. If we calculate the sum of the roots ($c_j + \bar{c}_j = 2a_j$) and the product of the roots ($c_j \cdot \bar{c}_j = -1$), we find that $c_j$ and $\bar{c}_j$ are the exact roots of this equation:
$$x^2 - 2a_j x - 1 = 0$$Because of this, the sequence generated by that nasty fraction perfectly obeys a simple linear recurrence:
$$U_{m+1} = 2a_j U_m + U_{m-1}$$(With starting values $U_0 = 0$ and $U_1 = 1$).
In number theory, this is known as a Lucas sequence.
Do you see what just happened? We don’t need the square roots. We don’t need $c_j$, $\bar{c}_j$, or $b_j$. To evaluate that terrifying fraction, we just need to calculate the $(n+1)$-th term of this simple integer sequence.
And because we know that $2a_j = 2\cos \frac{j\pi}{k+1}$, and we already know how to represent $2\cos\theta$ as a simple integer $w + w^{-1}$ in our Finite Field, we can evaluate this entire formula using nothing but basic 64-bit modular arithmetic.
Attempt 1: Matrix Exponentiation
To find the $N$-th term of a linear recurrence quickly, standard computer science dictates matrix exponentiation.
By representing the transition as a $2 \times 2$ matrix, we can find the $N$-th term in $O(\log N)$ time:
$$\begin{pmatrix} U_{m+1} \\ U_m \end{pmatrix} = \begin{pmatrix} 2a_j & 1 \\ 1 & 0 \end{pmatrix}^m \begin{pmatrix} 1 \\ 0 \end{pmatrix}$$I implemented this. It worked flawlessly, and because we dropped the inner loop of the grid, the time complexity plummeted from $O(N \times K)$ down to $O(K \log N)$.
Anton Strikes Again: Fast Doubling
I showed Anton the updated matrix code. He immediately pointed out that standard matrix exponentiation, while conceptually correct, was doing unnecessary work.
When you square a $2 \times 2$ matrix, you have to perform 8 multiplications and 4 additions. But a Lucas sequence possesses deep internal symmetry. You don’t actually need all four elements of the matrix; you only need to track two adjacent terms in the sequence, $U_k$ and $U_{k+1}$.
Instead of a generic matrix multiplication, Anton suggested a direct approach using the Fast Doubling Algorithm. You can leapfrog forward through the sequence using these exact identities:
- $U_{2k} = U_k(2U_{k+1} - a U_k)$
- $U_{2k+1} = U_k^2 + U_{k+1}^2$ (where $a = 2a_j$)
This is mathematically identical to the matrix exponentiation, but computationally, it is vastly superior. We reduced the workload per bit of $N$ from 8 multiplications down to just 3 multiplications. By using __builtin_clzll(n) to instantly find the highest set bit and skipping leading zeros, we mathematically vaporized over 60% of the CPU cycles in the innermost loop.
Amdahl’s Law and the Prime Sieve
When I implemented the Fast Doubling approach, something funny happened. The math became so blindingly fast that the program’s bottleneck completely shifted. My CPU was now spending almost all of its time just trying to find the prime numbers for the Chinese Remainder Theorem universes.
Welcome to Amdahl’s Law. To make the program faster, I had to optimize the prime sieve.
First, I parallelized the prime search. Instead of a standard OpenMP for loop, I created a shared-state worker pool. All 16 cores of my CPU spun up into a while loop, using atomic locks (#pragma omp atomic capture) to grab the next candidate number, test it, and add it to a shared array.
Second, I optimized the Miller-Rabin primality test. Previously, I was testing 12 different prime bases to guarantee 100% accuracy. But thanks to research by Jim Sinclair, we know that you can definitively prove the primality of any 64-bit integer using exactly 7 specific bases: 2, 325, 9375, 28178, 450775, 9780504, and 1795265022. By dropping from 12 checks down to 7, the sieve sped up by another 40%.
The Final Benchmark
We took a 2D physical graph problem. We transformed it into a 1D Lucas sequence. We evaluated it using Fast Doubling inside a Finite Field, parallelized the prime hunting using OpenMP atomic locks, and stitched it together using a GMP Divide-and-Conquer binary tree.
It was time to run the benchmarks on my MacBook Pro one last time.
I ran the $1024 \times 1024$ grid. It finished in 0.131 seconds.
I ran the $2048 \times 2048$ grid (the one that previously took 23 seconds). It finished in 1.154 seconds.
Finally, I ran the $4096 \times 4096$ grid. The exact same grid that, just a few days prior, had taken my machine a grueling 6 minutes to calculate. The terminal churned out the perfectly exact 2.1-million-digit integer.
It took 9.218 seconds.
Unbelievable.
The Code: Generation 5 (The Ultimate Engine)
This is the final, ultimate form of the domino engine. By collapsing the 2D grid into a 1D Lucas sequence and leaping through it using the Fast Doubling algorithm inside our multi-core Finite Field architecture, we obliterate the computational bottlenecks. This code can calculate a massive $10000 \times 10000$ grid in a reasonable amount of time.
💻 View the code on GitHub: domino-1d-ff.c